
Derrière la barre de recherche la plus utilisée de la planète se cache une mécanique d’une sophistication rare. Chaque seconde, des milliards de requêtes traversent les serveurs de Google, déclenchant une chaîne de traitements invisibles mais redoutablement précis. Des robots qui sillonnent le web sans relâche, des index colossaux répartis sur des centres de données aux quatre coins du monde, des algorithmes capables de comprendre l’intention d’une question mal formulée — tout cela fonctionne en coulisses, à une vitesse que l’œil humain ne peut pas percevoir. Pour un dirigeant, un responsable marketing ou un entrepreneur B2B, comprendre ces rouages n’est pas une curiosité intellectuelle. C’est une nécessité stratégique. Parce que celui qui saisit comment Google sélectionne, classe et affiche les résultats dispose d’un avantage décisif pour construire une présence en ligne durable, attirer un trafic qualifié et transformer la visibilité en pipeline commercial réel.
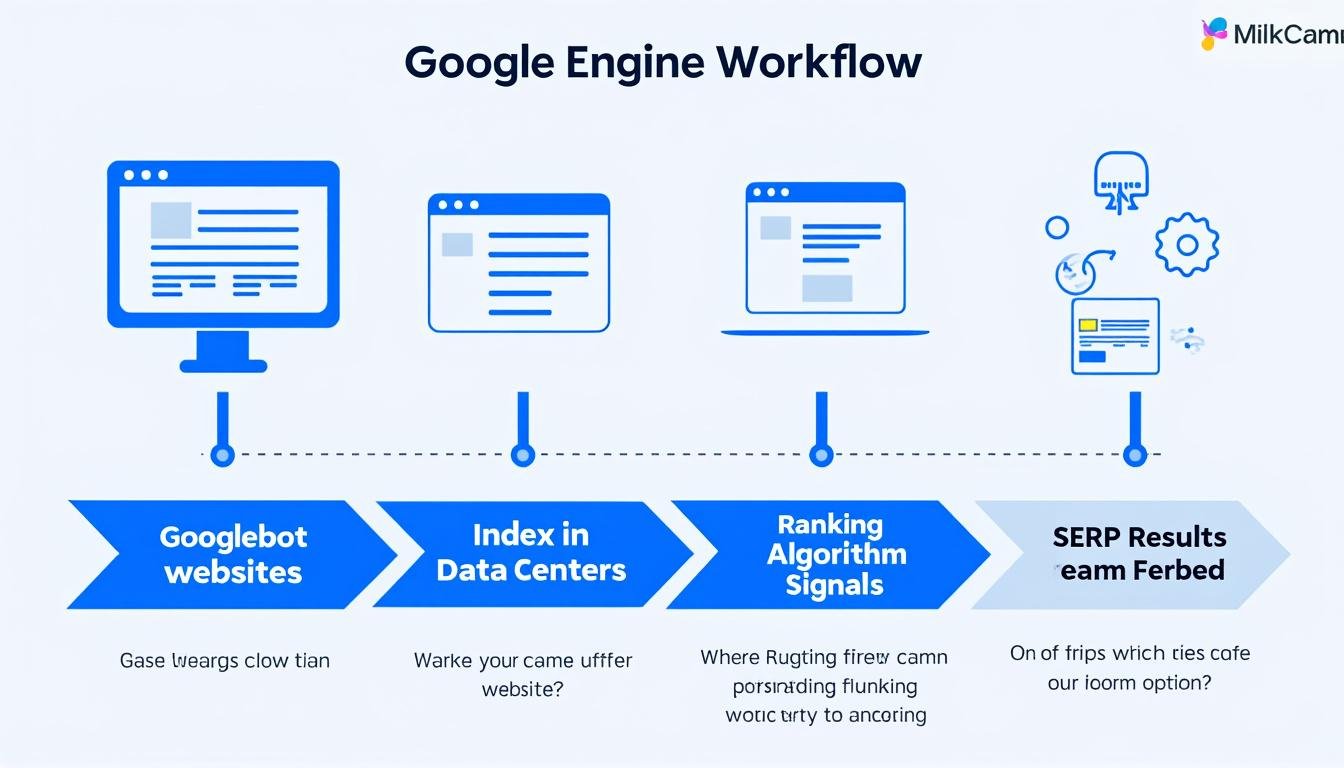
- Google fonctionne en trois étapes fondamentales : exploration (crawling), indexation et classement (ranking).
- Googlebot parcourt des milliards de pages en suivant les liens, sans relâche.
- L’algorithme évalue des centaines de signaux pour décider quelle page mérite la première position.
- Depuis 2019, l’IA (BERT, MUM) joue un rôle central dans la compréhension des intentions de recherche.
- Le SEO efficace consiste à comprendre ces mécanismes pour les aligner avec une stratégie de contenu et d’acquisition B2B.
Comment fonctionne Google : la mécanique des trois grandes étapes
Le fonctionnement de Google repose sur un enchaînement précis de trois phases : l’exploration, l’indexation et le classement. Chacune conditionne la suivante. Sans exploration, pas d’indexation. Sans indexation, pas de classement. Et sans classement, aucune visibilité pour votre site, aussi bon soit-il.
Comprendre cette logique séquentielle change radicalement la façon d’aborder le référencement naturel. Une PME B2B qui produit du contenu de qualité mais qui n’a pas configuré correctement son fichier robots.txt peut tout simplement disparaître des résultats, non par manque de pertinence, mais par une barrière technique que Googlebot ne peut pas franchir.
L’exploration : Googlebot, ce robot infatigable
Googlebot est le robot d’exploration de Google. Il visite des pages web en permanence, suit les liens internes et externes, détecte les nouvelles URLs, et remonte régulièrement sur les pages déjà connues pour vérifier si elles ont évolué. Ce processus, appelé crawling, constitue le point de départ de toute présence dans les résultats de recherche.
Sa logique de priorisation n’est pas aléatoire. Les domaines à fort PageRank, les sites mis à jour fréquemment et ceux bénéficiant de nouveaux liens entrants de qualité sont explorés plus souvent et plus en profondeur. À l’inverse, un site lent, instable ou dont l’architecture est mal structurée verra Googlebot réduire automatiquement sa fréquence de visite — c’est ce qu’on appelle le crawl budget throttling.
Lors de sa visite, le robot ne se contente pas de lire le texte. Il analyse le code source HTML, repère les balises meta robots, vérifie les directives du fichier robots.txt, extrait les données structurées (schema.org, JSON-LD), et identifie les ressources JavaScript à traiter ultérieurement via le Web Rendering Service. C’est une radiographie complète, exécutée en quelques millisecondes.
L’indexation : trier, classer, stocker à l’échelle planétaire
Une fois la page explorée, elle entre dans le processus d’indexation. Google l’analyse en profondeur pour déterminer sa langue, son thème, ses entités sémantiques, et la version canonique à retenir si des doublons existent. Ce tri est fondamental : l’index de Google contient des centaines de milliards de pages, réparties sur des centres de données distribués dans le monde entier.
Les modèles de traitement du langage naturel comme BERT (introduit en 2019) et MUM permettent à Google de vectoriser le contenu — c’est-à-dire de le représenter mathématiquement — pour en saisir le sens profond, au-delà des simples mots-clés. Une page qui explique « comment améliorer la rentabilité d’une campagne emailing B2B » sera associée à des entités comme « marketing automation », « taux de conversion » ou « cold emailing », même si ces termes n’apparaissent pas explicitement dans le texte.
Pour les entreprises qui souhaitent comprendre en détail comment fonctionne la recherche Google selon la documentation officielle, cette phase d’indexation est celle qui conditionne directement la qualité de la visibilité dans les résultats de recherche.
Le fonctionnement de l’algorithme Google : ce qui décide du classement
Le classement, ou ranking, est l’étape qui obsède les équipes SEO. C’est ici que Google décide, parmi des milliers de pages indexées sur un même sujet, lesquelles méritent d’apparaître en première page — et dans quel ordre. L’algorithme mobilise des centaines de signaux simultanément, et aucun n’agit seul.
Le PageRank, créé dès 1998 par Larry Page et Sergey Brin à Stanford, reste l’un des fondements. Il mesure l’autorité d’une page à partir du nombre et de la qualité des liens qui pointent vers elle. Mais à ce signal historique s’en sont ajoutés des dizaines d’autres au fil des années : la fraîcheur du contenu, l’expérience utilisateur, la compatibilité mobile, la vitesse de chargement mesurée via les Core Web Vitals, ou encore la compréhension de l’intention de recherche.
Les signaux de classement les plus déterminants
Voici les principaux critères que l’algorithme de Google évalue pour chaque requête :
- Qualité et pertinence du contenu : richesse sémantique, exhaustivité, originalité, réponse précise à l’intention de recherche.
- Autorité du domaine et des pages : volume et qualité des backlinks entrants, maillage interne cohérent.
- Expérience utilisateur : temps de chargement (LCP), stabilité visuelle (CLS), interactivité (INP), compatibilité mobile.
- Signaux E-E-A-T : Experience, Expertise, Authoritativeness, Trustworthiness — la crédibilité perçue de la source.
- Intention de recherche : adéquation entre le type de contenu proposé (informatif, transactionnel, navigationnel) et ce que cherche réellement l’utilisateur.
- Données structurées : balisage schema.org qui enrichit la compréhension sémantique et peut déclencher des rich snippets.
- Fraîcheur du contenu : pertinence temporelle, notamment pour les requêtes liées à l’actualité ou aux tendances sectorielles.
Pour mieux cerner les grandes étapes du fonctionnement de Google et leur impact concret sur le positionnement, il est utile de croiser la documentation officielle avec des analyses terrain issues de cas réels.
| Étape | Mécanisme principal | Impact SEO direct |
|---|---|---|
| Crawling | Googlebot suit les liens, scanne les pages | Découverte des nouvelles pages et mise à jour des existantes |
| Indexation | Analyse sémantique, détection d’entités, vectorisation BERT/MUM | Présence ou absence dans les résultats selon pertinence et qualité |
| Ranking | Algorithme multi-signaux (PageRank, UX, contenu, liens) | Position dans les SERP, visibilité, trafic qualifié |
| Présentation SERP | Interface adaptée au device et à l’intention | Taux de clic (CTR), rich snippets, featured snippets, AI Overview |
L’évolution historique de Google : comprendre pour mieux anticiper
Google n’a pas toujours fonctionné comme aujourd’hui. L’algorithme de 1998 est aussi éloigné du moteur actuel qu’un téléphone à cadran l’est d’un smartphone. Retracer cette évolution permet de comprendre la logique profonde qui guide chaque mise à jour — et d’anticiper les prochaines.
Au départ, l’algorithme se résumait presque entièrement au PageRank : plus une page recevait de liens, plus elle était considérée comme importante. Ce modèle simple a rapidement engendré des dérives — achats massifs de liens, fermes de contenu, bourrage de mots-clés. Google a alors commencé à durcir les règles, mise à jour après mise à jour.
Les grandes étapes qui ont transformé le moteur
En 2011, la mise à jour Panda a ciblé les contenus de faible qualité et les sites dupliqués. Un an plus tard, Penguin s’attaquait aux pratiques de netlinking artificiel. Ces deux algorithmes ont restructuré en profondeur le paysage SEO, pénalisant des milliers de sites qui avaient bâti leur visibilité sur des techniques manipulatoires.
Le tournant sémantique est arrivé en 2013 avec Hummingbird. Pour la première fois, Google cherchait à comprendre l’intention d’une requête complexe, et non plus à simplement matcher des mots-clés. C’était le début d’une nouvelle ère, confirmée en 2015 avec RankBrain, qui intégrait le machine learning pour traiter les requêtes nouvelles ou ambiguës.
En 2018, le Mobile First Indexing renversait la hiérarchie : désormais, Google évalue d’abord la version mobile d’un site. Pour les entreprises B2B dont les sites n’étaient pas optimisés pour les smartphones, la facture a été lourde en termes de positionnement. En 2019, BERT a franchi une nouvelle étape en permettant au moteur de saisir le contexte des mots dans une phrase — « comment vendre sans forcer » n’est plus simplement « vendre » et « forcer », mais une intention précise à interpréter.
Les Core Web Vitals sont devenus facteurs de classement officiels en 2021, intégrant l’expérience technique dans l’équation du référencement. Puis, l’IA générative s’est imposée progressivement dans les SERP avec les AI Overviews, redessinant la façon dont les utilisateurs consomment les réponses — sans nécessairement cliquer sur un lien.
L’évolution de Google
à travers les années
Cliquez sur une carte pour en savoir plus · Filtrez par thème
Comment Google évalue la pertinence : l’intention de recherche au cœur du système
Derrière chaque requête tapée dans la barre de recherche se cache une intention — et Google a consacré des années de recherche à la déchiffrer avec une précision croissante. Ce n’est plus le nombre de fois où un mot-clé apparaît sur une page qui détermine sa pertinence, mais la capacité du contenu à répondre précisément à ce que l’utilisateur cherche à accomplir.
On distingue généralement quatre types d’intentions : informationnelle (comprendre, apprendre), navigationnelle (trouver un site précis), transactionnelle (acheter, télécharger) et commerciale (comparer avant d’acheter). Un responsable commercial B2B qui tape « meilleur CRM pour PME » n’a pas la même intention qu’un étudiant qui cherche « définition CRM ». L’algorithme le sait, et classe différemment ces deux requêtes malgré leur proximité lexicale.
Pourquoi l’intention de recherche redéfinit le SEO B2B
Pour une agence ou une entreprise B2B, aligner son contenu sur les intentions de recherche réelles de sa cible est devenu l’axe principal d’une stratégie SEO performante. Produire un article sur « comment choisir un outil d’automatisation marketing » répondra mieux à une intention commerciale que de simplement lister des fonctionnalités produit.
Cette logique s’applique directement à la structuration du maillage interne et des pages clés. Si vous souhaitez approfondir des sujets connexes comme les stratégies SEO sur les plateformes e-commerce, la même logique d’intention s’applique : chaque page doit répondre à une question précise que se pose votre prospect à un stade donné de son parcours d’achat.
Le signal de satisfaction utilisateur — le fait qu’un internaute clique sur un résultat et ne revienne pas immédiatement sur Google pour chercher ailleurs — reste l’un des indicateurs les plus puissants de la qualité d’une page. Ce comportement, parfois appelé « pogo-sticking », est interprété comme un signal négatif par l’algorithme. Un contenu qui retient l’attention, répond précisément et incite à explorer le site bénéficie donc d’un avantage structurel dans les résultats de recherche.
Optimiser sa présence face à Google : méthode concrète pour les entreprises B2B
Comprendre le fonctionnement de Google, c’est bien. Traduire cette compréhension en actions concrètes qui génèrent du trafic qualifié et des leads, c’est mieux. Voici une méthode structurée, directement applicable pour une PME ou une équipe marketing B2B qui veut transformer sa visibilité en résultats mesurables.
Les erreurs fréquentes qui sabotent le référencement
Avant d’agir, il faut identifier ce qui freine. Plusieurs erreurs reviennent systématiquement dans les audits SEO :
- Bloquer Googlebot accidentellement via une directive mal configurée dans robots.txt ou une balise noindex laissée sur des pages stratégiques après un développement.
- Négliger le maillage interne : des pages clés enfouies à 5 clics de la page d’accueil ne seront ni bien explorées, ni bien valorisées par l’algorithme.
- Produire du contenu sans intention de recherche précise : rédiger pour « parler de son métier » sans cibler des requêtes réelles génère du contenu fantôme — indexé mais jamais consulté.
- Ignorer les Core Web Vitals : un site lent sur mobile pénalise directement le classement, indépendamment de la qualité du contenu.
- Multiplier les pages en duplicate content sans canonical clairement défini, ce qui dilue l’autorité et brouille l’indexation.
Plan d’action pour structurer son référencement
La première action concrète consiste à analyser les logs serveur. Cet exercice, souvent négligé, révèle exactement quelles pages Googlebot visite, à quelle fréquence, et où il rencontre des obstacles. Des outils comme Screaming Frog Log File Analyser ou OnCrawl rendent cet audit accessible, même sans expertise technique avancée.
Ensuite, il s’agit de prioriser le maillage interne vers les pages génératrices de leads : pages de services, landing pages, études de cas. Chaque nouveau contenu publié doit pointer vers ces pages clés via des ancres contextuelles pertinentes. Cette circulation de l’autorité interne accélère leur montée en positionnement.
La structuration des données structurées (JSON-LD, schema.org) est souvent sous-exploitée en B2B. Pourtant, un article bien balisé peut décrocher un featured snippet, une FAQ enrichie dans les SERP, ou une place dans les AI Overviews — autant de formats qui augmentent significativement le taux de clic sans nécessiter de remonter dans le classement classique.
Il est également pertinent de penser à la diversification de la visibilité. Si vous travaillez un secteur spécifique, pensez à votre présence sur des plateformes tierces : une stratégie de veille commerciale bien menée permet d’identifier les signaux de marché et d’alimenter une production de contenu cohérente avec ce que recherchent réellement vos prospects.
Enfin, mesurer. Chaque action SEO doit être reliée à un indicateur : trafic organique qualifié, taux de conversion des pages de destination, coût d’acquisition SEO vs payant, nombre de leads issus du canal organique. Sans mesure, il est impossible de prioriser, d’ajuster et de justifier les investissements en contenu et en optimisation technique.
Pour aller plus loin sur les mécanismes concrets du moteur, cette analyse détaillée du fonctionnement de Google propose une lecture technique complémentaire, utile pour les profils qui souhaitent approfondir les aspects d’architecture et d’exploration avancée.
Qu’est-ce que le crawl budget et pourquoi est-ce important pour le SEO ?
Le crawl budget désigne le nombre de pages que Googlebot accepte d’explorer sur un site dans un temps donné. Pour les sites volumineux, ce budget est limité. S’il est gaspillé sur des pages inutiles (erreurs 404, pages dupliquées, URLs de filtres sans valeur), les pages stratégiques risquent d’être explorées moins souvent, voire ignorées. Optimiser le crawl budget passe par la suppression ou le blocage des pages sans valeur SEO et par un maillage interne qui oriente Googlebot vers les contenus prioritaires.
Combien de temps faut-il pour qu’une nouvelle page soit indexée par Google ?
Le délai d’indexation varie selon l’autorité du domaine, la fréquence de publication et la qualité du maillage interne. Pour un site bien établi avec des backlinks de qualité, une nouvelle page peut être indexée en quelques heures. Pour un site récent ou peu autorité, cela peut prendre plusieurs semaines. Soumettre l’URL via la Search Console, la lier depuis la page d’accueil ou obtenir un lien externe depuis une page déjà crawlée régulièrement accélère le processus.
Qu’est-ce que l’intention de recherche et pourquoi Google en tient-il compte ?
L’intention de recherche désigne l’objectif réel derrière une requête : s’informer, comparer, acheter ou trouver un site précis. Google analyse des millions de comportements utilisateurs pour déduire quelle intention correspond à chaque requête. Un contenu aligné sur l’intention correcte sera mieux classé qu’un contenu techniquement parfait mais mal ciblé. Pour le SEO B2B, cela signifie qu’une page commerciale ne doit pas répondre à une intention informationnelle, et vice versa.
Les backlinks sont-ils toujours aussi importants pour le classement Google en 2026 ?
Les backlinks restent l’un des signaux les plus puissants dans l’algorithme de Google. Leur impact a évolué : la qualité prime largement sur la quantité. Un lien depuis un site de référence dans votre secteur vaut infiniment plus que cent liens depuis des annuaires génériques. Le profil de liens doit paraître naturel — diversifié en termes d’ancres, de types de sites sources et de rythme d’acquisition. Les pratiques de netlinking artificiel sont détectées avec une précision croissante depuis les mises à jour Penguin et leurs déclinaisons.
Les AI Overviews de Google remplacent-ils les résultats classiques ?
Les AI Overviews (anciennement Search Generative Experience) sont des réponses générées par l’IA de Google qui s’affichent au-dessus des résultats organiques classiques pour certaines requêtes. Ils ne remplacent pas les résultats, mais captent une partie du trafic sur les requêtes informationnelles. Pour les entreprises B2B, l’impact est surtout visible sur les requêtes génériques. Les requêtes commerciales à forte intention d’achat restent moins touchées. S’y préparer implique de structurer le contenu avec des données structurées, des réponses directes et des formats facilement citables par une IA.